

 Jim Blakley
Jim Blakley

By Jim Blakley, Living Edge Lab Associate Director, Carnegie Mellon University
In 2014, when my team at the time began working with modern artificial intelligence technologies, industry innovation focus was on neural network architecture . Every day, it seemed a new, more complex neural network was introduced (e.g., AlexNet, GoogLeNet, ResNet, MobileNet, VGG and beyond). We were amazed at the rapid accuracy improvements achieved for tasks like computer vision and object detection. That innovation vector was quickly joined by two others: large scale dataset collection and labeling (e.g., ImageNet , Flickr100m , YouTube8m and CIFAR-10 and 100 ) and training process scaling and optimization using hardware acceleration with GPUs, FPGAs and ASICs and smarter algorithms like reinforcement learning and neural network compression. The next vector, training and inferencing framework innovation, was kicked off with The University of California, Berkeley Caffe 1.0 release. Then followed Torch, Tensorflow, PyTorch, MXNet, Keras, PaddlePaddle and others . While research and innovation in these for areas is still very robust, the next vector – application creation -- the one that brings home the bacon – is moving into prominence.

Applications are by definition diverse, specific and fragmented. There are artificial intelligence applications across every industry and many types of problems (e.g., traffic intersection management, medical image analysis, fraud detection, securities valuation, crop monitoring). Turning core technologies into solutions to real world problems involves two main tasks:
- Customization and improvement of the technologies to make them “fit for purpose” for the specific application.
- Stitching together the individual technologies into an integrated whole so that the application actually does what it is intended to do.
These tasks are the domain of systems research and systems engineering – where I’ve spent most of my career and are the focus of the Carnegie Mellon University (CMU) Edge Computing Research Team and the Living Edge Lab .
In my last blog , I described an important class of augmented reality applications (AR) called Wearable Cognitive Assistance (WCA). WCA applications provide automated real time hints and guidance to users by analyzing the actions of the user through an AR head mounted display (HMD) while they complete a task. For his PhD thesis , recent CMU graduate Junjue Wang looked at two WCA systems challenges and created open software frameworks to begin to address them.
- WCA applications are inherently video based and require real time video detection of application specific objects. Application creation is usually iterative and, over time, the object types that need to be recognized change as the application workflow evolves. Rapidly collecting training data for application-specific objects, labeling that data and retraining the application detectors is necessary to make WCA applications practical. Since collecting and labeling data is still a very manual process, automation can help speed up the data scientist’s dataset creation efforts. The OpenTPOD framework helps here.
- Like many user interactive applications, WCA applications have at core a user workflow model for executing a series of steps in response to user inputs. A primary task of the application developer is designing this workflow – with all its failure cases – then implementing and evolving it. OpenWorkFlow is a framework for WCA-specific workflow creation and editing.
Here’s an example from my “FlatTire” application from my last blog . In this application, the first two simple steps are:
- Collect the tools and supplies you need (bicycle pump, tire levers and a new tube). This step requires an object detector for each of the three items and to recognize that all three are present at the same time before it moves to …
- Remove the tire and wheel from the frame. Now, the application looks for a bicycle wheel on a bicycle fork. It first must see those two objects followed by a bicycle wheel alone to determine that the wheel has been removed.
Suppose I now wanted to insist that the user also has a patch kit before starting. I need to train a patch kit detector and update the workflow to now look for all four objects before moving to step two. The many necessary changes and error handlers that will come up during user testing mean that this modification process must be repeatable and streamlined.
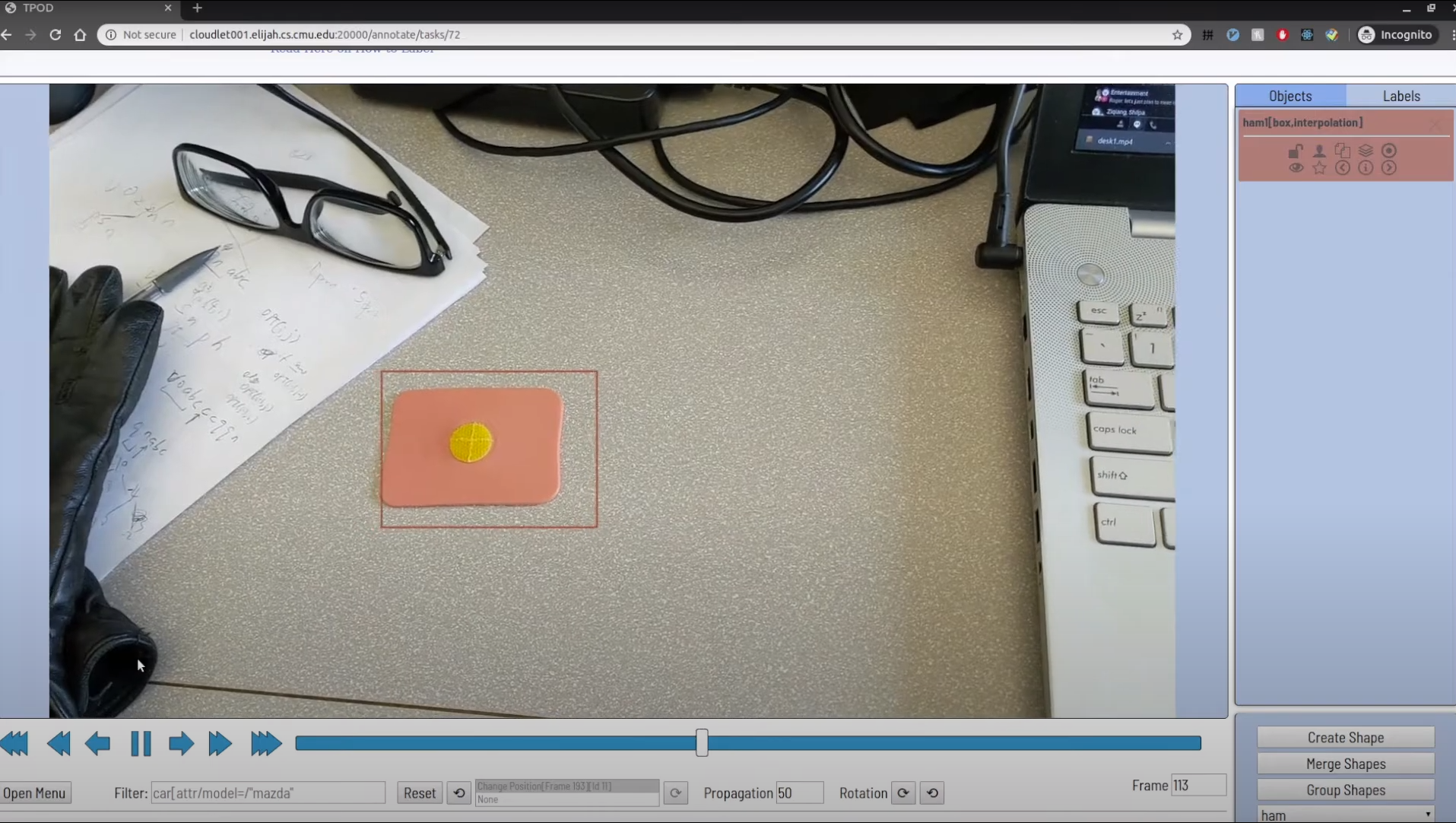
OpenTPOD (Tool for Painless Object Detection) accelerates the WCA object detector development process by automating many of the human steps and integrating training platforms directly into the tool. To use OpenTPOD, I collected a series of short videos of bikes, wheels, tires, etc. in a variety of lighting and positions. I uploaded them into OpenTPOD and used the GUI based labeling tool [1] to put bounding boxes around the key objects on a few frames. OpenTPOD extrapolates those labels across the video set to create a large set of labeled training images. It then uploaded the images into Tensorflow to train a downloadable object detector. While OpenTPOD was designed as a WCA tool, it can be used for creating object detectors for any video-centric application. The OpenTPOD GUI is shown at left.

Once I had the detector, I used OpenWorkFlow to define the
state machine
for my application. OpenWorkFlow has both a GUI and a Python API. I found the API easier and more flexible for both initial design and modification. The output from OpenWorkFlow and OpenTPOD can be used directly by the
Gabriel
framework to execute the application. The state machine code for the first two states described above are shown below.
Here’s a diagram of how OpenTPOD and OpenWorkFlow and Gabriel fit together.
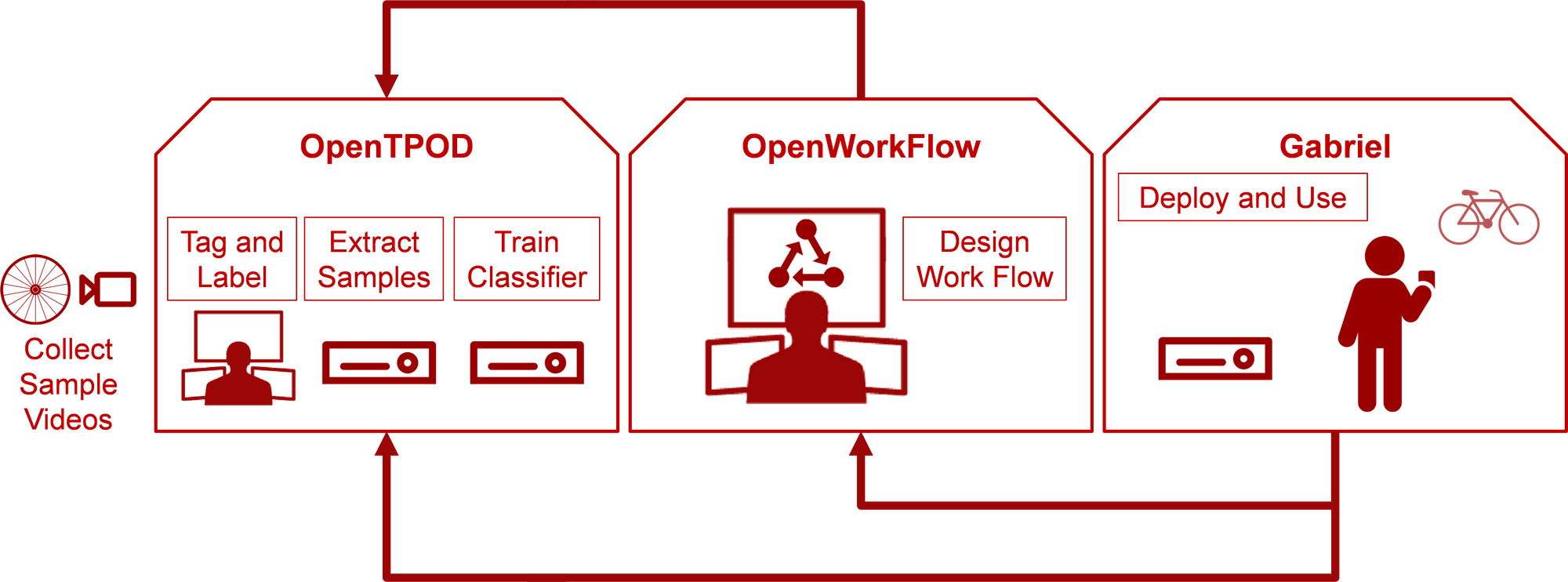
We continue to evolve these three frameworks with a current focus on making OpenTPOD support more training frameworks and enabling easier labeling iteration with new data and object classes.
To try out the code, visit https://github.com/cmusatyalab/OpenTPOD and https://github.com/cmusatyalab/OpenWorkflow . To learn more about Wearable Cognitive Assistance and our efforts, check out the references below.
© 2020 Carnegie Mellon University
Previous Blogs
" When the Trainer Can't Be There ", Jim Blakley, Open Edge Computing Initiative, August 2020.
Publications
· " Augmenting Cognition Through Edge Computing ", Satyanarayanan, M., Davies, N. IEEE Computer, Volume 52, Number 7, July 2019
· " An Application Platform for Wearable Cognitive Assistance ", Chen, Z., PhD thesis, Computer Science Department, Carnegie Mellon University., Technical Report CMU-CS-18-104, May 2018.
· ‘‘ An Empirical Study of Latency in an Emerging Class of Edge Computing Applications for Wearable Cognitive Assistance ’’, Chen, Z., Hu, W., Wang, J., Zhao, S., Amos, B., Wu, G., Ha, K., Elgazzar, K., Pillai, P., Klatzky, R., Siewiorek, D., Satyanarayanan, M. , Proceedings of the Second ACM/IEEE Symposium on Edge Computing, Fremont, CA, October 2017
· " Towards Wearable Cognitive Assistance ", Ha, K., Chen, Z., Hu, W., Richter, W., Pillai, P., Satyanarayanan, M., Proceedings of the Twelfth International Conference on Mobile Systems, Applications and Services (MobiSys 2014), Bretton Woods, NH, June 2014
· “ Scaling Wearable Cognitive Assistance ”, Junjue Wang PhD. Thesis, May 2020
Videos
· OpenTPOD Overview (February 2020)
· OpenWorkflow Overview (February 2020)
· IKEA Stool Assembly: Wearable Cognitive Assistant (August 2017)
· RibLoc System for Surgical Repair of Ribs: Wearable Cognitive Assistant (January 2017)
· Making a Sandwich: Google Glass and Microsoft Hololens Versions of a Wearable Cognitive Assistant (January 2017)
For all papers, publications, code and video from the CMU Edge Computing Research Team see:
http://elijah.cs.cmu.edu/
[1] Based on the Computer Vision Annotation Tool (CVAT) .